Aggregation
Instruction results can be automatically aggregated by Tachyon, so that when a user clicks on an aggregated result, Tachyon then 'drills down' and displays the data that was aggregated.
To aggregate results you need to return at least two columns from the instruction.
One column will be used to group the results. Results in each group are then aggregated by one or more of the remaining columns in the result set. Aggregation means computing some value across all the results, such as their sum, min, max etc.
Note
You can group results by multiple columns as well. However in our example we will group by only one column to keep things simple.
We will modify the instruction schema and instruction that we have been working with in order to set up aggregation.
Tip
See Instruction Definition Reference (AggregationJson) for more detail about Aggregation settings.
Note
TIMS allows you to author instructions which use aggregation but it cannot display the aggregated result nor does it support the ability to drill down. You will have to upload the instruction to Tachyon in order to utilize aggregation. When run under TIMS, only the raw (non-aggregated) results are displayed.
Configure Aggregation
Press the schema button and modify the schema to return two columns, myval1 and myval2 of type int32
Note
Use the + button to add additional columns to the schema.
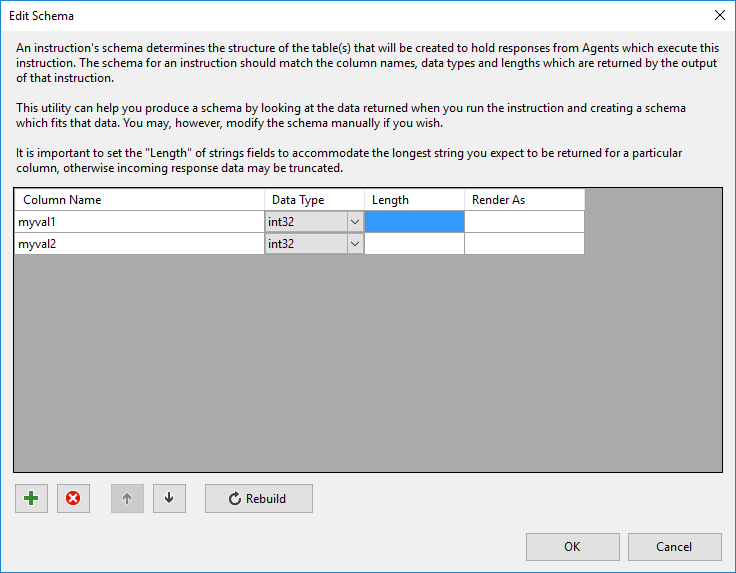
Press OK and then modify the instruction to read
select 1 myval1, 2 myval2;
Run the instruction and observe that values are returned for the two columns
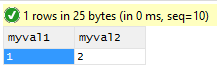
We will now define an aggregation for the results. This will control how the Tachyon server processes the raw results from each endpoint when this instruction is executed
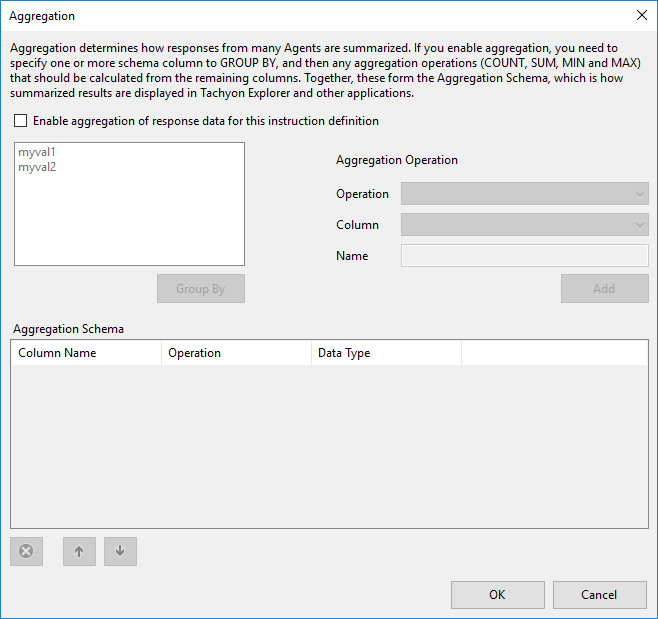
Enable aggregation and select a 'group by' column
First you must tick the 'Enable aggregation checkbox
Then select the column you wish the results to be grouped by on the server side. In this case we have selected that the results should be grouped by the 'myval1' column, by clicking the column name and then clicking the Group By button
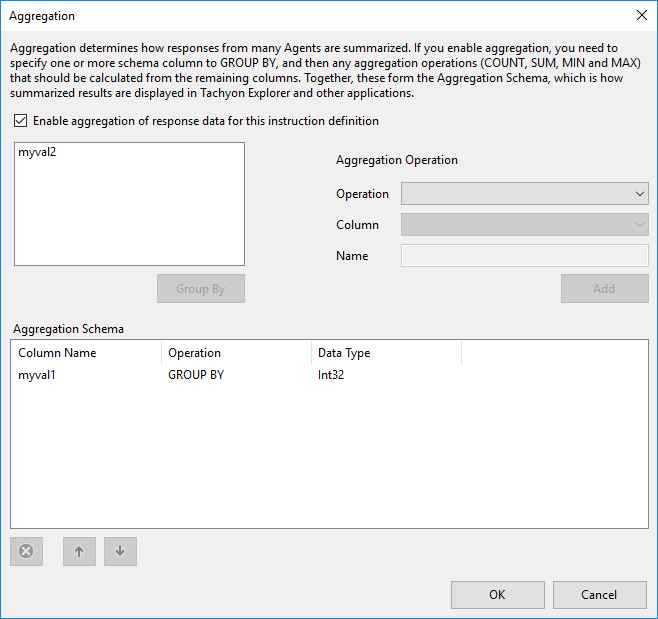
Choose an aggregation operation and a target column
Choose 'sum' from the operation dropdown list and choose the myval2 column from the column dropdown list
We will name the result 'SumofMyval2'
Then click Add to add the aggregation operation
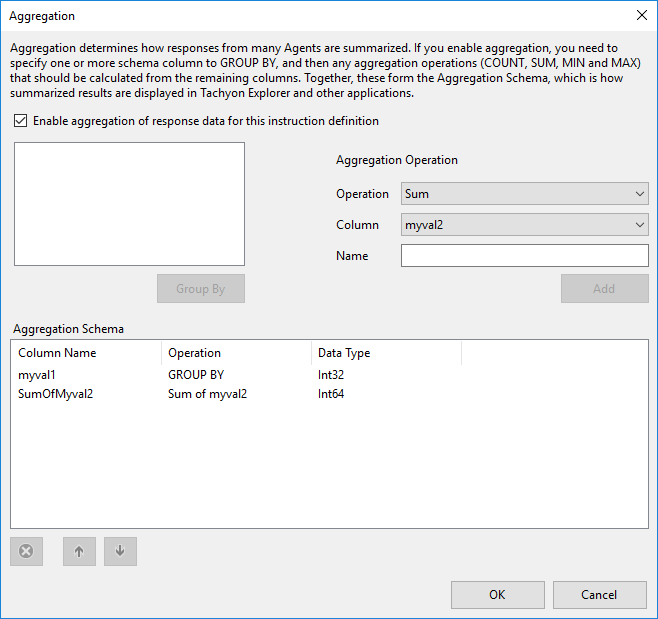
Press Ok to save changes
The aggregation data is added to the instruction XML file. It will look like this (note: the XML has been reformatted for clarity)
<AggregationJson>
<![CDATA[
{"Schema":[
{"Name":"myval1","Type":"int32","Length":"0"},
{"Name":"SumOfMyval2","Type":"int64","Length":"0"}
],
"GroupBy":"myval1","Operations":[{"Name":"SumOfMyval2","Type":"sum(myval2)"}]}
]]>
</AggregationJson>When data is collected by the Tachyon client, the results will be grouped by the value of the myval1 column for all devices that respond. Then, the myval2 column will show the sum of the values of each device's myval2 column results, for that particular grouping value returned in myval1. For example:
Raw data collected from all endpoints
Device | myval1 | myval2 |
|---|---|---|
D1 | 1 | 2 |
D1 | 1 | 3 |
D2 | 1 | 4 |
D2 | 2 | 1 |
D3 | 2 | 5 |
Aggregated data
myval1 | SumofMyval1 |
|---|---|
1 | 9 |
2 | 6 |
You can then 'drill down' by clicking on any aggregated row to view the raw data that was aggregated to produce the results.
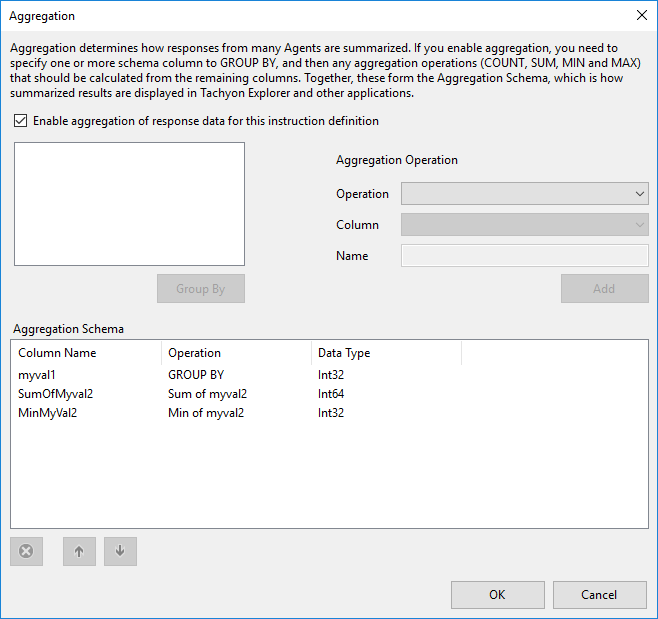
Computing multiple aggregated results
Just as you can group by multiple columns, you can compute aggregated results multiple times, either for the same column or for different columns.
These columns cannot be part of the aggregate grouping columns, however.
In the example below we compute both the sum of the myval2 columns returned and the minimum value of the myval2 columns.
Enabling and disabling aggregation
The 'enable aggregation' checkbox in the aggregation dialog allows you to disable aggregation at any time. However, note that if you do this, your current aggregation settings are immediately lost when you close the dialog.