Using the Reboot Summary report to improve your reboot strategy
Your organization should have a computer reboot strategy in order to:
Balance the urgency of security updates with the importance of user productivity and satisfaction
Ensure that relevant teams have a consensus on how to handle various kinds of security updates and other activities that require reboots
To ensure that tools that manage reboots (such as Microsoft System Center Configuration Manager) are used appropriately
Give your end-users a predictable experience
The NightWatchman Reboot Summary report allows you to improve your reboot strategy by allowing you to understand.
When are your computers being rebooted and how extensively?
Is that the activity level you and the security department expected?
Are users adversely affected by reboots?
How long are those reboots taking?
Are users likely to be disinclined to reboot when asked due to long reboots?
If you allow users to choose when to reboot after you've applied changes (and thus those changes are "pending"), how many reboots are pending now?
How many in the recent past?
How long do reboots pend? Is that acceptable?
By reviewing the Reboot Summary report you can understand your organization's actual reboot experience. Does it match what you would be expect from your reboot strategy? You should review the report with your security department to ensure that reboots pend (and thus security vulnerabilities are still open) according to their expectations. You should review the report with people responsible for the end user experience and productivity to ensure reboots are occurring at an acceptable rate.
The answers to these questions will also vary over time. And some business units or regions might be more cooperative (or more adversely affected) than others. Some computers might be more affected than others. The Reboot Summary report allows you to drill down on the above questions to fine-tune your reboot strategy.
Based on what you and related teams find, you might want to:
Talk to business units or regional coordinators to encourage more rapid reboots by users
Use ConfigMgr or similar tools differently to reboot more or less frequently
Improve your computer startup scripts or similar technical elements involved in the computer reboots
Opportunities to improve to improve your reboot strategy
The following graphs illustrate hypothetical examples of reboot-related activity for 3 months at an organization with over 12,000 clients. On this page we have:
Reboot Clients per Day
Reboot Speed
Pending Reboots
How Long Reboots Pend
Next Steps
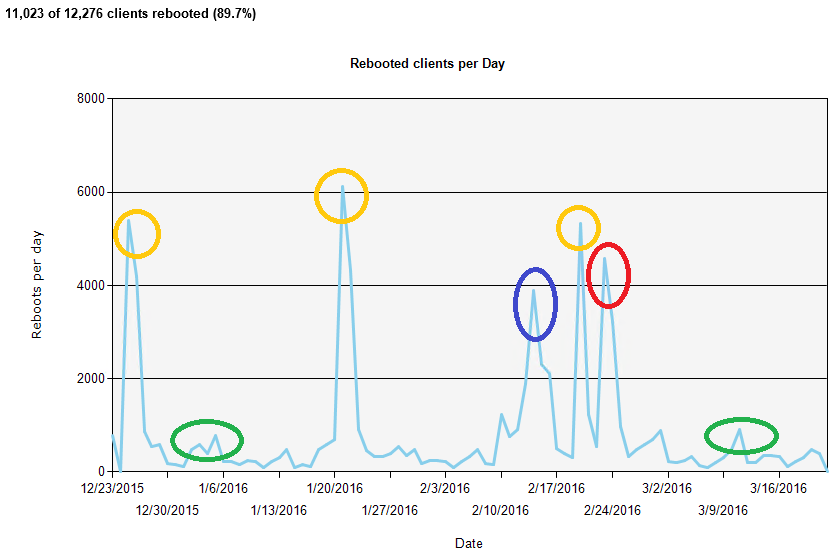
Rebooted clients per day
The organization illustrated in this graph does a week of testing of software updates released on Microsoft's "Patch Tuesday", then installs them on all applicable computers in the organization but allows up to a week for the users to reboot the computers. Some users reboot in that week but many wait for the reboots to be enforced.
The orange circles indicate the peak days when reboots are enforced for Patch Tuesday. In this case the behavior is as expected and is probably acceptable, though it would be good to encourage more users to reboot voluntarily at their convenience.
The red circle indicates a large number of reboots soon after the third Patch Tuesday. This might be surprising and could indicate that some of the changes during that Patch Tuesday induced a second round of rebooting for many users. That was likely frustrating for the users, so it would be ideal to avoid that if possible.
The blue circle indicates a large round of rebooting not related to Patch Tuesday. There was a lot of rebooting in the days before and after the peak, so almost the whole organization was affected. This might have been necessary due to an important company-wide release, but it might have also been due to a poorly configured deployment. The deployment could also have been phased over a longer period in order to spread out the effect on the business unit activities. The event should be reviewed to look for opportunities to improve the reboot strategy.
The green circles indicate other periods of increased reboot activity but are not nearly as concerning as the period highlighted by the blue circle.
 |
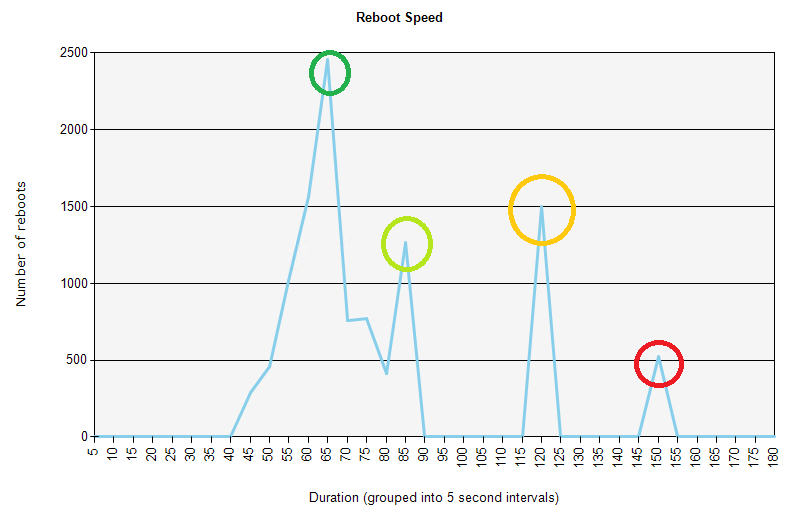
Reboot speed
In this example we can see that most computers reboot in 60 seconds, with a bell curve of some computers rebooting a little faster or a little slower than that. That is reasonable.
There is a large number of computers that are an exception to this and take about 85 seconds to reboot. When you investigate you might find that these are older computers that are due to be replaced anyway.
The orange circle highlights a spike that is a concern in that there are a large number of computers taking two minutes to reboot. That is likely frustrating to users and could discourage them from rebooting when needed for security updates or other reasons. That should be investigated in order to understand why they're taking two minutes and how that can be improved.
The red circle highlights another concern where some computers are taking 2.5 minutes to reboot. The number is much smaller than the issue illustrated by the orange circle but it is also worth investigating.
 |
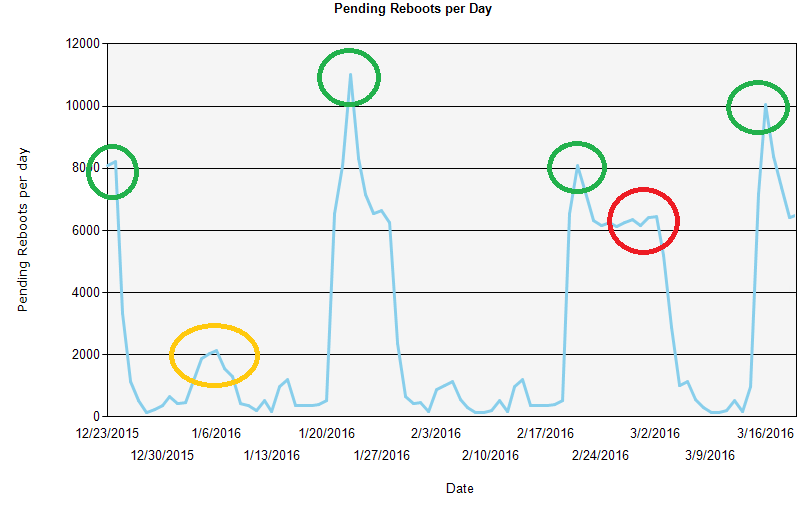
Pending reboots
The pending reboots graph shows how many reboots are currently pending (about 6500) and how many were pending. In this example we see spikes as Patch Tuesday updates are installed. The number quickly decreases for up to a week as some users voluntarily reboot. The number then dramatically decreases as reboots are enforced after one week.
However, Patch Tuesday deployment enforced in late February had pending reboots for much longer than normal (the red circle). This could be a serious failure of the reboot enforcement mechanism. Possibly the deployment was misconfigured.
There was also an unusual spike in pending reboots in January. However, it is not very large, so maybe it was just a special deployment for a subset of computers that needed a particular improvement.
 |
How long reboots pend
Here we can see that many reboots pend for a week (the green circle), which is the period from when the Patch Tuesday patches are installed and reboots are enforced. However, there are also a lot of reboots done right away or in the first 4 days, as seen in the light green circle. Those reboots are done voluntarily by the users at their convenience.
The most concerning issue in this example is that there are a considerable number of reboots that take close to 4 weeks. These are likely unacceptable to the security department and may be enforced by a tool they are using. Work should be done to minimize that spike, such as improving earlier reboot enforcement effectiveness and encouraging better user behavior.
Next steps
To investigate issues such as those illustrated, you should get a list of computers that where affected from the NightWatchman data. You can then check a small subset of those computers to understand the root cause or causes. If all or most of the computers in the subset you check all have one or two root causes, it's reasonable to extrapolate that those are the root causes of the issue as a whole. The size of the subset depends on how consistent the issue is and how comfortable you are with the explanation. Often 5 to 15 computers are enough, but you might want to check 30 or more. Depending on the nature of the issue, you might talk to the affected users, check the event log on their computers, or review the specifications and configuration of their computers.